



Monolith, Modular, Mesh: Modern architecture for modern data platforms
This blog is the second in a series that highlights exciting developments within the world of data platforms. On behalf of ALTEN, I am happy to share these new technologies which we are already successfully applying at our projects.
Modularity is a hot topic within the field of software design. Especially since the explosion of microservices architectures in the 2010s, development teams all over the world have been scrambling to see which (parts) of their applications they could break down into smaller, more easily maintainable pieces. Within the world of data platforms, modularity is still a relative newcomer, but it is a welcome one. I would even say, amidst all the current debate, that modularity is currently the only type of “unbundling” which benefits the modern data stack.
Introducing modularity in data platform architectures is key to designing future-proof data platforms. Modularity, which can be applied on different levels, can greatly enhance the flexibility and scalability of a data platform. Later in this article I will highlight why this is the case, but first I will discuss a brief history of data platform architecture to understand why its emergence is logical and timely. At the end of this article I will discuss the latest application of modularity within data platform architectures: the data mesh.
Starting off, I think it’s important to give the two important definitions that are used throughout this article. Within the context of this article, I define modular as something which consists of multiple components which can be developed, maintained, scaled, or can function independently from the other components. The term modular can be used on many different levels: e.g., platform level, code level, and others. As the opposite to modular, I define monolithic as something which doesn’t consist of components which can be developed, maintained, scaled, or can function independently. Again, this term can be used on many different levels.

Past: monolithic data platforms
Before the rise of cloud technologies, the standard for building a centralized, analytical data platform was to build a data warehouse located in an on-premises data center. The flow of data within these traditional data warehouses follows the Extract-Transform-Load (ETL) paradigm. This means that the extraction, transformation, and loading of data is encapsulated in the same process, even though these are very different operations. Because the different operations within traditional data warehouses can’t be carried out independently from each other, the architecture of these data warehouses is monolithic.
Monolithic data platforms bring about several problems. First of all, monolithic data platforms have flexibility issues. Replacing components within the application is hard because if data flows are end-to-end and thus sequential (characteristic within the ETL paradigm), every step of the data flow depends on the previous one. Then, making changes has a high chance of breaking something downstream. This makes extensive regression testing crucial.
The second problem with monolithic data platforms is their maintainability (or rather the lack thereof). Every new data product within the platform needs a new ETL process to be defined. This leads to a new end-to-end data flow which needs to be defined, or an existing flow which needs to be expanded. Either way, this makes the ETL codebase expand (nearly) linearly with each new data product and, in reality, this brings about an enormous ETL code spaghetti which is hard to maintain. Combined with the high risk of downstream products breaking, this doesn’t allow for a pleasant development or operations experience.
Lastly, monolithic data platforms have limited scalability. Because these platforms are monolithic, they allow vertical scaling perfectly fine, but won’t lend themselves to horizontal scaling. Since vertical scaling is (mostly) finite, monolithic data platforms with larger volumes of data will sooner or later reach their capacity limits, resulting in data processing times of multiple hours.
This doesn’t mean that the monolithic data platform is dead. Evidently, if there is no business case for adding technical complexity by introducing modularity, please refrain from resorting to anything else but a simple monolith. Additionally, in greenfield or proof-of-concept scenarios it can be beneficial to start with a minimum viable product which can immediately deliver business value. Then using an agile development process, you can incrementally improve and migrate to a more modular architecture when necessary.

Present: the rise of modularity
In the old on-premises world, enormous sums of money went into purchasing enterprise software packages from one or two vendors, to gather everything necessary for building a data platform. Vendors had every incentive to make their applications as big and interdependent as possible, to create vendor lock-in. With the rise of the open-source community in the 2000s, which traditional vendors like Microsoft tried their very best to prevent , the collection of available applications fragmented into smaller, more specialized software. The rise in popularity and adoption of open-source software accelerated even more when cloud technologies became ubiquitous in the 2010s. Pillars from the open-source mindset, especially the aversion to vendor lock-in and a DIY mentality supported by open-source programming languages, have since been embraced by the majority of the software and data (platform) engineering communities.
Because of this change in mindset, various organizations and their engineers increasingly discovered and developed various alternatives to the old data platform technology and fixed the limitations that were exposed by growing data volumes. A single trend unifies all these new advances of existing technology within the world of data platforms: increasing modularity.
Modularity can exist at various levels within platform architecture. I will discuss the most common forms of modularity for data platform architecture, based on the problems from the monolithic data platform era they aim to solve.
Scalability
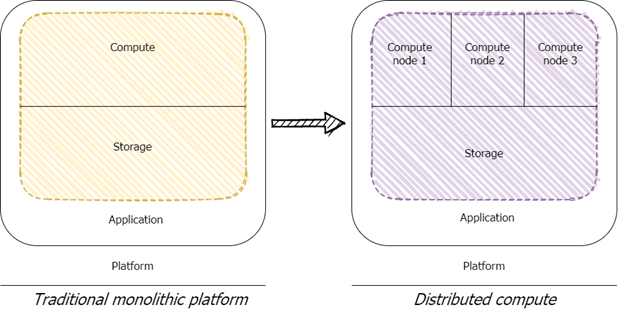
One of the main problems on the agenda for organizations with big data workloads was the scalability problem of traditional, monolithic data platforms. Monolithic data platforms only lend themselves well to vertical scaling: the need for more processing power meant upgrading to servers with more firepower and capacity. This limitation on scaling possibilities meant your scalability was finite to the point of the current technological advances in processors and storage. Therefore, there was a crucial need for solutions which allowed horizontal scaling. And so, distributed computing skyrocketed in popularity. The idea behind distributed computing is to divide a processing workload over multiple machines, which then execute their respective tasks in parallel and come together in the end to assemble the result. Distributed computing theoretically enables infinite scaling (horizontally) because the only limit to how many machines you can put next to each other, is the software coordinating the effort. Within the data platform landscape, the most popular implementation of distributed computing used to be the open-source big data processing framework Apache Hadoop (MapReduce) but has since been dethroned by Apache Spark because of its improved performance and improved support for streaming data.
Distributed computing effectively solved an important part of the scalability problem of monolithic data platforms. Distributed data processing frameworks can, however, not really be classified as introducing modularity into a platform architecture, since computing nodes within a distributed system are highly dependent on each other. Nonetheless, it did signal a change in mentality for data platform architecture from relying on bulky, standalone servers, to creatively dividing workloads over multiple components. And, even more importantly, it laid the foundation for the rise of a pivotal concept within data platform architecture: the separation of storage and compute power.
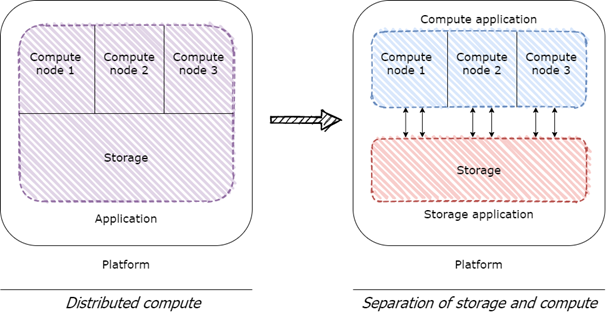
The idea behind distributed computing, i.e., dividing workloads over multiple machines to allow for increased scalability, was indicative of a newly emerged dogma: dividing a large monolithic application into smaller components improves the application’s scalability, flexibility, and maintainability. From this philosophy, a logical next step for data platforms was to separate a data platform’s storage and compute resources into separate components which can be scaled separately from each other. After all, the main performance bottleneck of traditional data warehouse servers lay in the limited capacities for scaling processing power, not in the limited capacities for scaling storage. Since the rise of distributed computing allowed for new possibilities in horizontal (theoretically infinite) scaling of processing power, separating compute resources from storage resources was an obvious choice for creating scalable data platform architectures.
Dividing storage and compute into separate applications was an essential step for enabling data platforms to handle big data workloads. It’s the first main shift from monolithic data platforms to modular data platforms. And, because the cloud abstracts the complex management of clusters of separated compute and storage resources, modernizing data platform architectures became very feasible even for smaller organizations.
Flexibility
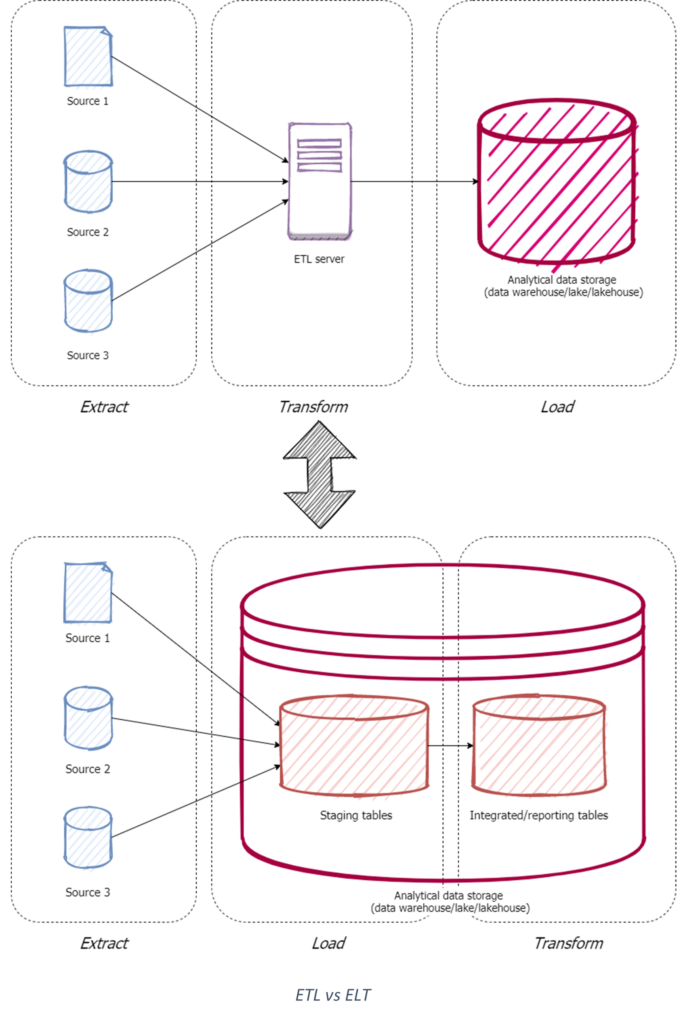
After processing power had been divided into distributed systems, and compute and storage resources in turn had been separated into distinct applications, it was time for the next vital paradigm shift within data platform architecture: the shift from the Extract-Transform-Load (ETL) to the Extract-Load-Transform (ELT) paradigm. Don’t let the seemingly minor change in terminology fool you; this shift has been crucial in improving the flexibility of data platforms, as well as greatly improving the time-to-value of data products.
As previously discussed, the ETL paradigm caused numerous problems with the flexibility and consequently the maintainability of traditional data platforms. End-to-end data flows where ingestion and transformation are one process, ensure problems with the entire data flow when either of those two complex steps fail. Therefore, it was once again time to introduce some modularity in the architecture of data platforms, enabled by the newly minted standard of separating storage and compute resources. Because the relatively cheap storage capacity could now be scaled independently from the expensive compute resources for data processing, growing data volumes were no longer a real bottleneck. Especially in the cloud, data architects and engineers no longer needed to worry much about the limits of data storage. Previously, architects and engineers had to think of how to extract source data from operational systems efficiently into a temporary staging area for transformations before loading it into a data warehouse, because of that data warehouse’s storage limits. Now, they could just extract and load the source data directly into a data warehouse or lake and do the transformations later, effectively creating a permanent staging area where raw data is kept for advanced analytics, lineage, or auditing use cases. This decoupling of data ingestion and data transformation is known as the ELT paradigm.
Alongside serving new use cases, the ELT paradigm fixes some of the aforementioned problems from the ETL era. ELT killed the necessity for end-to-end data flows and thus allowed for more modular data processing. Every step of the ingestion and transformation processes could now be defined as separate blocks of processing logic. Moreover, code for data ingestion and transformation could now be made generic in some places, because the code didn’t have to be tailored to a specific combination of source, transformation, and destination. This makes for more maintainable code bases, which don’t have to expand linearly for each new data flow. Each data flow could now exist, albeit not always fully, out of modular, reusable building blocks.
Microservices for data
The newly conceived possibilities for creating modular, reusable building blocks for defining data processing logic enabled by the ELT paradigm, closely resembles a parallel trend that started a few years earlier within the field of software engineering: the rise of microservices architectures.
The microservices architecture pattern involves dividing a single application into multiple loosely coupled, fine-grained services, each of which can be developed, deployed, and operated independently from one another. Microservices communicate using protocols which abstract the services’ internal logic into standardized interfaces (e.g., REST). In other words, microservices are one of the best examples of modularity within an application, following the definition used in this article.
Microservices architectures have been immensely popular over the past decade or so. It is the pinnacle of the modern dogma of breaking down large monoliths into smaller, more maintainable, more flexible, and more scalable components. Moreover, all of the aforementioned developments within data platform architecture (i.e., distributed computing, separation of storage and compute, the rise of ELT) have made the timing perfect for also introducing microservices architectures into the world of data platforms.
Within modern data platforms, the pattern of using microservices for data processing is becoming more prevalent. Small, generic processes are increasingly encapsulated in containerized microservices (built and orchestrated using Docker and Kubernetes) which can be used for both batch processing and real-time, event-based processing. Cloud services like AWS Lambda and Azure Functions make it even easier to achieve the same results by abstracting most of the underlying infrastructure so that engineers can focus on coding the processing logic.
It is, however, important to note that introducing microservices for data processing isn’t necessarily the right solution for your organization’s data platform. Microservices usually require knowledge of imperative programming languages such as Python, but this knowledge isn’t always available within an organization. Organizations without complex data processing needs or programming skills can mostly be satisfied by using low-code cloud solutions such as Azure Data Factory or AWS Glue or even any other orchestration tool that is able to run SQL stored procedures. These tools don’t require you to take on the same technical complexity as creating your own microservices.
Modularity of the future: organization level modularity and the data mesh
Thus far, we have seen many examples of modularity that involve dividing a centralized data platform into smaller components. Recently, a new way of introducing modularity has emerged within the world of data platform architecture: achieving organizational-level modularity by means of a data mesh architecture. Before we go into the details of this exciting new development, we must first explore the architectural problems from which the data mesh has emerged.
Over the past few years, many organizations have adopted the modularity principles mentioned in this article to improve on the scalability, flexibility, and maintainability of their data platforms. Often, organizations build centralized data platforms, developed and operated by centralized data teams consisting of specialized data professionals. Every data product is therefore manufactured by centralized teams, who have to cope with overflowing backlogs containing the analytics needs and wishes for an entire organization. In smaller organizations, this is usually not problematic: the collection of data products is still fairly organized and usually the business domain is small enough to comprehend for a single data team. But, in larger organizations, a centralized data team can become a bottleneck for the time-to-value for data products. Additionally, the value of data products in itself can decrease, because it is nearly impossible for centralized teams to have domain knowledge of all business segments.
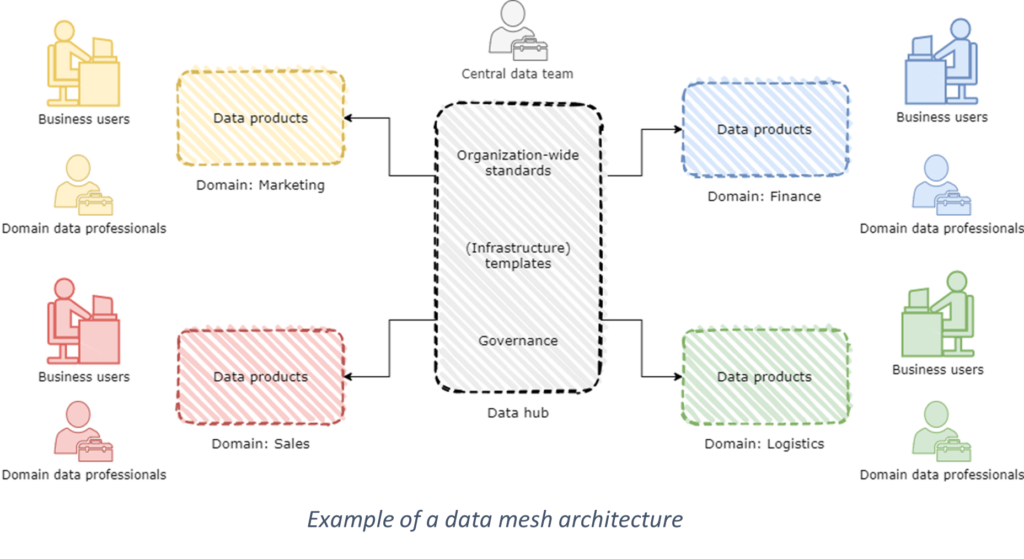
The data mesh architecture has been brought into existence to manage these problems. A data mesh architecture steps away from developing and operating a centralized data platform, and instead advocates for developing and operating decentralized data platforms for various business domains, owned by decentralized teams, but governed by organization-wide standards. It provides a solution for bottlenecks in the time-to-value for data products in centralized data teams, and ensures that domain knowledge is always available in the teams responsible for creating those data products. Data mesh architecture is in fact a form of modularity on the organizational level: it requires breaking down a centralized data platform into multiple decentralized data platforms, such that they can be loosely coupled but never dependent on each other.
It is important to stress the importance of the difference between decentralized data platforms in a data mesh, and inaccessible data siloes. Fragmenting your data landscape under the disguise of a data mesh architecture ensures you’ll encounter the same problems as in the era before the data warehouse: valuable datasets will be stuck in operational systems without any possibilities for integration and enrichment. Instead, decentralized data platforms serve data products based on centralized governance standards and standardization for interoperability. For example, a product team should be able to discover and use the data products of a financial domain within the same organization for their own purposes (of course, given that they have the clearance to see this data). This interoperability forms the backbone of a data mesh’s success; interoperability is an absolute must for enabling domain data ownership of integrated data, instead of creating fragmented and inaccessible siloes of operational data.
(An in-depth analysis of data mesh architecture unfortunately lies beyond the scope of this article, but I highly recommend reading Zhamak Dehghani’s founding paper and the numerous contributions by others that have built upon it.)
Just like a microservices architecture, a data mesh architecture isn’t a one-size-fits-all solution. The primary advantage, solving bottlenecks that block the creation of valuable data products, is mainly applicable to large organizations. The business case for smaller organizations usually doesn’t justify the technical and organizational complexity a data mesh architecture brings. Bottlenecks in the development of data products only exist when the demand for data products within an organization is high, which means the organization’s data literacy is also high. Therefore, organizations with lower data literacy can easily go without the complexity of introducing modularity on the organizational level.
Conclusion
Modern (cloud) technologies have brought about numerous possibilities for revolutionizing data platform architecture. Modularity is the new standard, and rightfully so. Even though monolithic applications still have their own use cases, introducing a little modularity in your data platform can work wonders for its flexibility, scalability, and maintainability. Many modern cloud-based data platforms already feature distributed computing, separation of storage and compute resources, and already follow the ELT paradigm. Still, many data platform architectures could gain some additional advantage from introducing modularity in the form of microservices, given that the added complexity is justified by the business case. And if that still doesn’t satisfy your organization’s flexibility, scalability, and maintainability requirements, it might be time to introduce organizational-level modularity and migrate to a data mesh.
I am eager to see how modularity in data platform architecture evolves over time and which new concepts or drawbacks will emerge. Every paradigm shift has its limits, and I’m sure that in ten years a sequel to this article will point out all the limits of our current methods of introducing modularity at the platform- and organizational-levels.
The third and last part in this series will be a case study about the challenges that occur when architecting and building the data platforms of the future. Stay tuned!
Axel van ‘t Westeinde
Would you like to read more ALTEN blogs? Please click here.








