



This blog is the third in a series that highlights exciting developments within the world of data platforms. On behalf of ALTEN, I am happy to share these new technologies which we are already successfully applying at our projects. This time it is about batch and stream processing.
In one of my previous articles , I gave a brief introduction to the data lakehouse concept and why it’s taking the data world by storm. By combining the high performance of data warehouses with the scalability, cost-efficiency, and flexibility of data lakes, a data lakehouse provides possibilities for getting the best of both worlds in terms of analytical data storage and processing within modern data platforms. In this article, I will highlight how a lakehouse architecture can unify batch and real-time data processing flows and which challenges arise during implementation. These lessons are based on recent experiences for one of our clients at ALTEN.
Greek architectures
Many modern cloud data platforms today separate the data flows for historical analytics and real-time analytics, respectively nicknamed a ‘cold’ and ‘hot’ path. This architectural pattern is also known as a lambda (Λ) architecture. (This Greek letter is chosen because, just like the architecture, it branches out in two paths.) The cold path in a lambda architecture utilizes batch-oriented data processing methods to handle incoming data with a given frequency (e.g., daily). Because batch processing methods are unsuitable for real-time analytics, the hot path is intended for using streaming methods to give live views of incoming data.
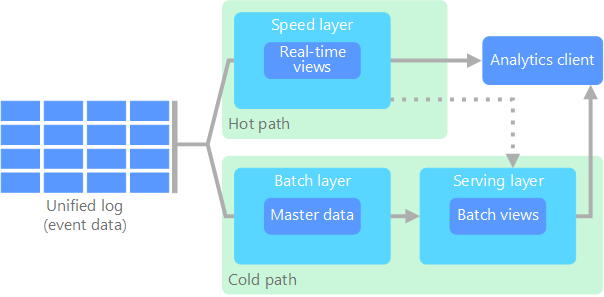
The main reason to opt for a lambda architecture is to enable real-time analytical insights within your organization. The batch processing methods used in a cold path are too resource-intensive to use for (near) real-time processing, mainly when dealing with larger volumes of data. Utilizing a hot path for real-time views on incoming data can support time-critical business processes. Unfortunately, it does come with a drawback: the quality of the real-time data can vary. One of the reasons batch processing is resource-intensive and time consuming, is that it aims to give a comprehensive and accurate representation of the data. The hot paths in lambda architectures have no such ambitions. Some of the transformations necessary for integrating new with existing data are too resource intensive to perform in a hot path. Therefore, the stream processing in a hot path can be seen more as a ‘quick and dirty’ view on incoming data than as the most recent representation of an organization’s state of affairs.
Another drawback of the lambda architecture is that both the hot and cold paths within the data platform will feature separate resources with separate codebases. Lambda architectures therefore introduce technical complexity which impedes development and maintenance. Naturally, the data industry has been searching for alternatives which alleviate these shortcomings.
One of the current alternatives is a kappa architecture. A kappa architecture solely makes use of streaming technologies to process both streaming and batch data. Because the kappa architecture considers data streams to be immutable, one major drawback is that reprocessing a dataset involves ‘replaying’ the past streams to get to the correct representation. This requires the streaming applications (e.g., message queues/brokers) to store a significant amount of history, which impedes the applications’ performance and goes against their original purpose. However, this is fine when the proportion of batch data is relatively small compared to the proportion of streaming data.
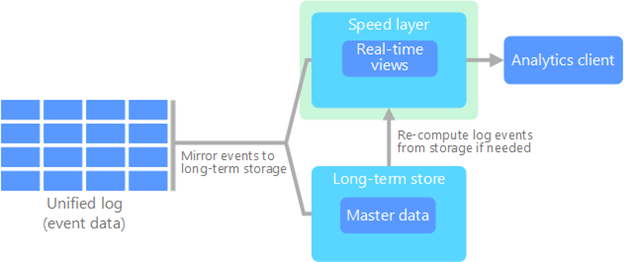
The shortcomings of lambda and kappa architectures have paved the road for a new type of Greek-letter architecture: the delta architecture. Just like the respective letters Λ and Δ, the difference between a lambda and delta architecture is that the delta architecture unifies the two ends of a lambda. Similar to a kappa architecture, it combines batch and streaming data in one processing flow with one codebase. The key difference between kappa and delta architectures is that in a delta architecture, every processed record is considered a ‘delta’ (i.e., change or differential, which can be of the type insert update , or delete ) record instead of an append-only record. (A delta architecture can therefore be seen as an upgrade to a kappa architecture, but less lightweight.) These two characteristics of a delta architecture aim to alleviate the pains of the lambda and kappa architectures.
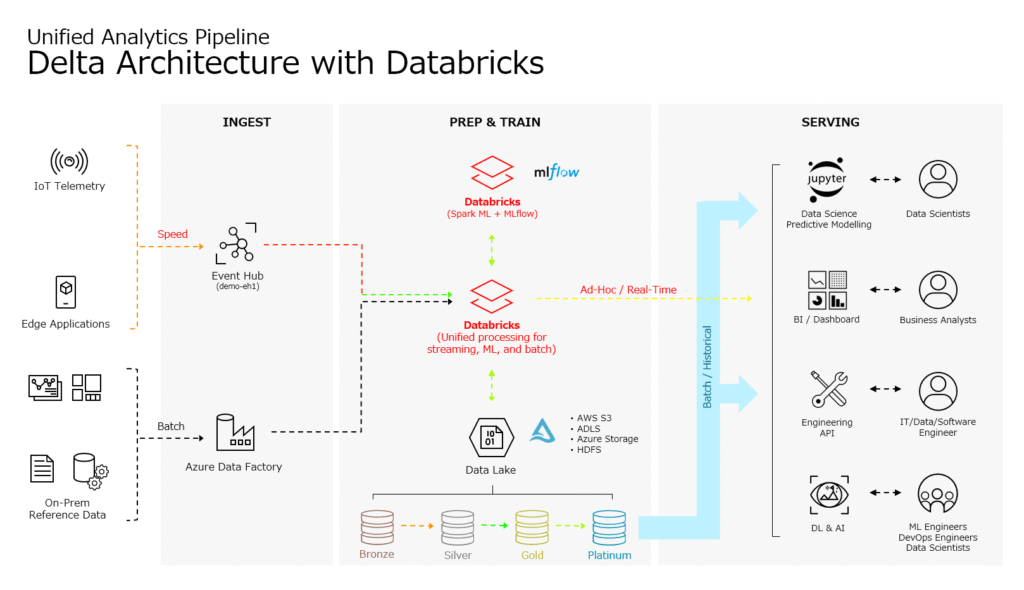
Delta architecture and the data lakehouse
Although the term ‘delta architecture’ has originally been coined by Databricks as a marketing term for their lakehouse implementation Delta Lake, it is relevant for almost every current lakehouse implementation out there. In lambda architectures, the setup includes almost always a data lake store for staging data and a data warehouse plus temporary (often NoSQL) data store for cold and hot path analytics respectively. In a lakehouse setup, the data warehouse and temporary data store become redundant because high-speed analytics can all be performed in the data lake store itself. (For more information on how this works, see this previous article .) Therefore, a data lakehouse setup lends itself perfectly for unifying batch and streaming data flows, and is nearly synonymous to a delta architecture.
Thanks to modern data processing engines such as Apache Spark Apache Flink , and Trino , unifying batch and streaming data flows while maintaining all logic in one codebase, has never been easier. Each of these processing engines also has support for at least one of the big three lakehouse implementations of this moment (Hudi, Delta Lake, and Iceberg), making delta architectures increasingly feasible for all organizations.
In the introduction of this article, I promised to discuss a couple of highlights from a recent delta architecture implementation we have done for one of our clients at ALTEN. Since Apache Spark is currently the most prevalent engine for big data processing, especially in a data lakehouse setup, we have chosen to implement a delta architecture using Apache Spark. Therefore, the rest of this article will be scoped to an implementation in Spark. Now, let’s move on to discussing how to implement a delta architecture using a data lakehouse setup.
Structured streaming
One of the key features in Spark, especially for unifying batch and streaming data flows, is structured streaming . In essence, it is a technique through which Spark breaks down incoming data into configurable micro-batches which can be processed using their DataFrame and Dataset APIs. The size of these micro-batches can be configured based on their desired timespan, ranging from seconds to minutes to hours, from continuous (process a micro-batch as soon as the previous one is done) to one-off (process everything that is available and then exit, similar to regular batch processing). Structured streaming effectively eliminates the need to maintain separate data flows for batch and streaming data, because it can handle both types of data, as well as anything in between. Hence, it is a perfect tool to build your delta architecture around.
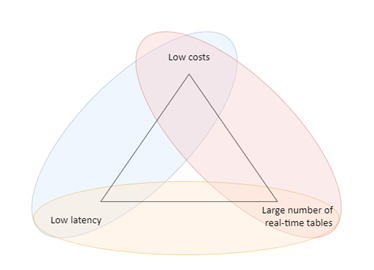
Unfortunately, structured streaming is not a one-way ticket to paradise. Creating a delta architecture using Spark involves a delicate balancing act of choosing between low latency, low costs, and a large number of (near) real-time tables. You can’t have all three of these factors at once due to the resource-intensive nature of Spark. It is important for every use case to discover the right balance between these three factors based on the requirements at hand. Building a data processing application for a lakehouse setup
Recently, one of our clients at ALTEN expressed the wish to start extracting and centralizing data from their operational systems. From an analytics perspective, their information landscape was in a greenfield state. This left many architectural options open for creating a centralized analytical platform. The main requirements we were given for data processing included: 1) the platform must have high flexibility to changes and support for different types of structured and unstructured data; 2) the platform must have the ability to process both batch data that is delivered periodically and change data capture feeds from operational systems; and 3) processed data must be highly auditable.
These requirements led us to almost immediately to advising a data lakehouse setup, including its corresponding medallion design pattern , because: 1) a lakehouse has more flexibility to schema changes and data model changes than a regular data warehouse, as well as support for any type of data; 2) a lakehouse eases the setup of a delta architecture where batch and streaming data flows are unified; and 3) the medallion design pattern within a data lakehouse ensures that the raw data is stored as-is, transformed data is stored separately, and every lakehouse implementation supports ‘time travel’ to previous states of a table.
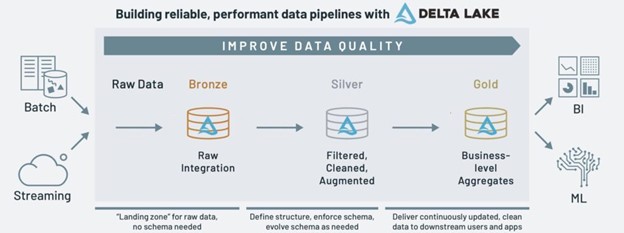
For the technical implementation of the data lakehouse, we have opted for Data Lake because it was the most technologically mature at the time. The obvious choice would be to go for a Delta Lake implementation using Databricks, because of their proprietary Delta Lake features. However, we had to choose Apache Spark Pools in Azure Synapse Analytics because of the easier integration with the existing RBAC permissions model in AAD and the more straightforward network isolation features. (Both of these features weren’t generally available in Databricks at the time.)
The most difficult part was designing a future-proof, modular data processing application which formed the heart of our data lakehouse. I will take you through the most important design choices we’ve made along the way.
Firstly, we have chosen to build the application’s processing logic as a regular Python project. While this sounds obvious (languages aside), nowadays many organizations opt for encapsulating their code in notebook form, either Jupyter or Databricks. Notebooks also have modular features, but usually come with some caveats that go against software engineering best practices. Two of them that come to mind are: 1) the source control workflow for notebooks often feels clunky and, in the case of Databricks notebooks, require you to utilize a still immature UI; and 2) importing modules from other files is done implicitly, which means it isn’t clear which functions or classes are imported when you import a notebook. The latter especially produces unexpected behavior when objects with the same name are imported. Thus, we have chosen to structure our Spark project folder around modular ‘jobs’ encapsulated in .py files, a Python package which contains reusable functions and classes, and a generic ‘spark-submit’ Bash script to launch any of the jobs in any environment by passing the relevant command line arguments. (The main inspiration for structuring our Spark project like this, can be found here ) This setup allows your files to be committed, reviewed, and merged using a standard Git workflow. It also allows for explicit importing of code from various modules.
Secondly, each job follows the same structure and utilizes Spark’s structured streaming API, such that batch and streaming jobs are syntactically the same. In fact, the black-and-white distinction between batch and streaming jobs has effectively been dismantled. Each job has its own ‘trigger window’, designating the amount of data included in a micro-batch expressed in a period of time, where every processing time on the spectrum from daily to sub-second is possible. Another benefit of unifying batch and stream processing jobs is that every job can easily be built using generic and reusable Python modules. This is further aided by our chosen project structure.
While this unification of batch and streaming data flows is elegant, it still requires careful balancing of the aforementioned factors: latency, cost, and the number of real-time tables. One of the requirements we had received was that every table had to be processed ‘near real-time’ to ensure the CDC records from their operational systems were processed as soon as possible. Since the definition of near real-time wasn’t set in stone, we agreed upon setting it at a maximum of 15 minutes delay, 24/7. This allowed us to keep costs within reasonable limits given the relatively small volumes of data that needed to be processed.
Another way we were able to keep costs low, is by running as many of the structured streams as possible in parallel on the same Spark cluster. Because of the relatively loose definition of near real-time and the small volumes of data, we were able to run all streams for roughly 70 source tables in parallel on the same cluster. Every stream is restarted daily, to allow for daily updates to the processing jobs.
Limitations and current developments
Even though Spark’s structured streaming capabilities form an exceptional opportunity for simplifying a data platform’s architecture, it isn’t a one-size-fits-all solution. Especially for use cases with smaller data volumes, like in the setup I described before, Spark can be a bit of overkill. The overhead of parallelization doesn’t weigh up to the performance benefits in small data use cases. Unfortunately, we were bound by Spark because it was the only method of creating a near real-time data lakehouse using Delta Lake at the time.
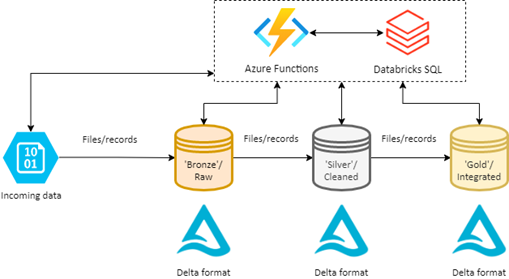
Luckily, the Delta Lake technology has been maturing at a rapid pace in the past few months. A cheaper and faster way to process relatively small datasets would be to use a serverless computing service like Azure Functions AWS Lambda . Since Databricks SQL has become generally available on Azure and AWS (and in public preview on GCP), every Databricks customer is now able to process their structured data into Delta Lake using an ODBC or JDBC connector. Combining the serverless computing services with Databricks SQL allows for a cheaper, much more lightweight data lakehouse implementation than by using Apache Spark. It also lowers the bar for implementing an event-driven processing application instead of a time-triggered one, thus further improving the processing time within a lakehouse.
If your organization is more into open-source technology, then keep an eye out for the delta-rs project . It is an open-source interface for Delta Lake outside of Apache Spark, including bindings for Rust, Python, and Ruby. As of yet, the project doesn’t support writes to Delta tables using Python and Ruby, but the project is quickly advancing.
Conclusion
The era of technically complex lambda architectures is coming to an end. Recent attempts to unify batch and real-time processing flows within data platforms are gaining traction, and rightfully so. Personally, I believe the delta architecture, especially combined with a data lakehouse at the heart of it, offers excellent opportunities for implementing a scalable and flexible data platform for both big and small data use cases. Both Spark structured streaming and the new Delta Lake interfaces for languages such as Python offer accessible and effective methods of unifying batch and streaming data flows. This opens up the possibilities for real-time analytics in more and more organizations.
This article concludes my three-part series on the future of data platform architecture. Haven’t read any of the previous articles? They can be found here and here . Make sure to stay tuned for new articles on current developments within the world of data! Axel van ’t Westeinde ALTEN offers many options to become a specialist in your field of expertise. Would you like to know more about working as an ALTEN consultant? Please click here.








